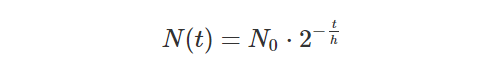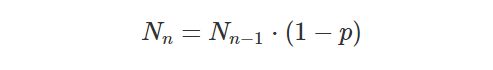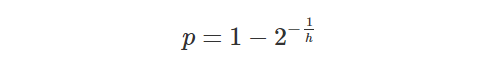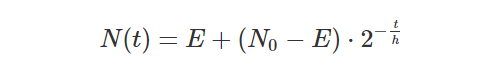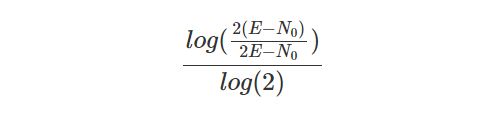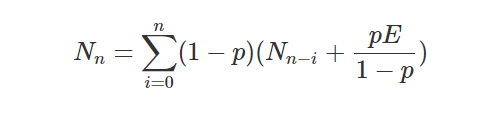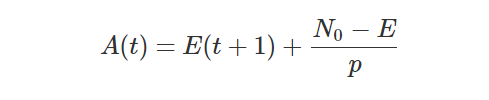Is something in your database dependent on time? If you think not, think again. I can assure you there are plenty of such things. But, as plentiful as your time-dependent objects are, as plentiful are the creative ways I’ve seen them handled. Trust me, when you screw up time, the failures of your implementation will be felt, painfully. This is, however, understandable given the complexity of time and its limited treatment in commonplace database literature. This article aims to introduce a terminology together with some best practices and considerations that should be addressed before implementing time in a database. It is inspired by the article “Kinds of Time” by Christian Kaul, and likely has significant overlaps, but provides my slightly different view.
Primary and Documentary Times
In essence there are two purposes time can serve in a database. Time can be of a primary nature or of a documentary nature. Time of a primary nature is part of your primary keys, and your database engine will, if modeled accordingly, automatically ensure temporal integrity with respect to it. Time of a documentary nature are data points that are of a time type, like a date, but that are not part of your primary keys. If you need any constraints imposed over your documentary time, you will have to build and maintain them yourself.
For integrity reasons, any primary time values must be comparable in such a way that they form a total order. Time of day, such as 12:59, cannot be used as it will repeat itself daily, giving you no option to determine if two instances of 12:59 coincided or happened in some succession. Because of this requirement, primary times are often expressed through some calendar convention, such as Julian day, Unix time, or perhaps most commonly ISO 8601, which even accommodates for leap seconds. It is worth noting that any time that is affected by daylight saving is not totally ordered. In Sweden the hour between 02:00 and 03:00 on the last Sunday of October is repeated every year. Even so and unfortunately, I see many databases here use local time as primary time.
A decent choice for a primary time would therefore be coordinated universal time (UTC). Expressed in ISO 8601, such a time looks like 2021-01-25T07:23:47.534Z. While this may look satisfactory, there is an additional concern. The precision of the data type used to store this time in the database may debilitate the total ordering. Somewhat surprisingly, and often nastily discovered, the precision of a datetime in SQL Server is 3 milliseconds. The final digit in a time expressed as above can only be 0, 3 or 7 in the database. While this particular choice is unintuitive, there is always a shortest time span that can be represented through a data type, called its chronon. For primary times, a data type with a chronon shorter than anything happening in succession is necessary to preserve the total ordering.
Given that primary times are parts of primary keys in the database and altering primary keys is normally time-consuming, the choice of data types should be made with care. Always picking the data type with the smallest chronon, such as datetime2(7) in SQL Server with a 100 nanosecond chronon, may affect performance. While it can store a time like 2007-05-02T19:58:47.1234567 it will use 8 bytes, compared to 3 bytes for the date type, if daily changes are sufficient. Keeping primary keys small should be paramount for any database designer, since smaller keys lowers total storage and increase insert and join performance.
Documentary times are not required to have a total ordering or even be temporally consistent, making it possible for versions overlapping in time. With so much leniency choices can be made with much less consideration. Naturally, there are cases when you want to impose the same restrictions to documentary times, particularly if you intend for them to behave as primary times at some point.
Particular Recurring Timepoints
There are some particular recurring timepoints of interest, and for some reason beyond my understanding there is no standardised way to express these. Some common ones are:
- The end of time.
- The beginning of time.
- Indefinitely.
- At an unknown time.
The end of time is what it sounds like, the infinite extension of time into the future. An application for this would be if you want to express a fact such as ‘I will love you forever’. Similarly, the beginning of time is the longest possible extension of time into the past. It could be applied in an expression such as ‘gravity has always been present in the universe’. Indefinitely is similar to these, but in this case we expect an actual point in time will come to pass after which a time interval is no longer open-ended. An application, with the slight but important difference from ‘forever’ is ‘I will cherish rock music until the day I die’ or ‘my hair will turn gray one day’. Finally, there is the unknown time. It can be used both for past and future events, such as ‘The price was raised, but nobody remembers when that happened’ and ‘We will raise the price the next time crops fail’.
From a storage perspective, databases normally provide one special value; NULL, that is (somewhat horrifyingly) often used for all purposes above. Practically one could possibly reason that unknown time could be used in place of indefinitely, which in turn could be used in place of the beginning and end of time. Semantically, some important nuances will then be lost. For example, the nuance lost by stating ‘I will love you until an unknown time’ may yield an entirely different outcome.
Ideally, and if your database permits user-defined types, data types which includes and separates these particular timepoints should be implemented. ISO 8601 should also be extended with ways to express these notions. There is an interesting discussion on how to express these by shema.org here, for anyone who wants to dive deeper, which suggests that standards may be coming. Regardless, you should consider how you intend to manage particular timepoints like these.
Named Timelines
Even if there is just one single time, there are many timelines. A timeline can be thought of as an interval of time (finite or infinite) over which events happen in a temporally consistent sequence. If two events can mess up each others bonds in time, such as one moving the other in time, then they definitely do not belong on the same timeline. For example, if I have an appointment in my calendar between 9:00 and 10:00 today it lives on a different timeline from the action of me, at 08:00, rescheduling it to the afternoon. Timelines can also be separated by the fact that the events they track pertain to completely different things, and it would only decrease readability and understandability to keep them together.
Borrowing the terminology of transitional modeling, following are some examples of timelines commonly discussed in computer science and database literature. There is so little consensus on the naming of these so understanding what they represent is what matters.
The Appearance Timeline
The appearance timeline contain points in time when some value was observed, became valid, or will come into effect in real life. It tracks the natural progression between values or states, both for attributes and relationships. Note that appearance timepoints may lie in the future, such as an already known price cut coming into effect on Black Friday.
In literature it is known by many different names: Valid time [Snodgrass], Effective time [Johnston], Application time [ANSI SQL:2011], and Changing time [Anchor modeling]. I also recall hearing these synonyms from forgotten sources: Utterance time, State time, Business time, Versioning time, and Statement time.
The Assertion Timeline
The assertion timeline contains points in time when some statement is subjectively assessed with respect to its certainty. In the simple case this is done by some system acting as the asserter and statements evaluating to either true or false. It is commonly used to track the correction or deletion of values or states, both for attributes and relationships. Note that assertion timepoints cannot lie in the future. If someone corrects the rebate for the upcoming price cut on Black Friday, this correction necessarily happens in the present.
In literature it is also known by many different names: Transaction time [Snodgrass], Assertion time [Johnston], System versioning time [ANSI SQL:2011], and Positing time [Anchor modeling]. I have heard less synonyms here from forgotten sources, only Falsification time and Evaluation time comes to mind.
For further reading on how to make uncertain assertions, to even being sure of the opposite, there is more information on transitional modeling in this series of articles.
The Recording Timeline
The recording timeline contains points in time at which information is stored in some kind of memory, typically when the data entered the database. This is very useful from a logging and later maintenance perspective. With it you can keep track of how quickly your database is growing on a per object basis, or revert to previous states of the database, perhaps after an erroneous load. It could have been the case that I sent all the price cuts for Black Friday into the production database but associated with the wrong products due to a faulty join.
In literature there are a couple of other names: Inscription time [Johnston] and Load date [Data Vault]. A very poor synonym I’ve seen used is Transaction time, which should be reserved for the assertion timeline alone.
The Structuring Timeline
The structuring timeline contains the point in time at which the information had a certain structure and constraints. Yes, structure and constraints change over time too. This process is referred to as schema versioning in literature, but few mention keeping a named time line for tracking when structural changes happened. If someone comes asking why there were no price cuts for Black Friday last year, you can safely assure them that ‘price cut’ was not part of your information structure at the time.
The only other name I have seen is Schema Versioning Time, but it has a too technical ring to it, in my opinion.
Unnamed Timelines
Unnamed timelines are all the points in time that do not fall within any of your named timelines. There will be values in your database that are of a time type, but that are not immediately put onto named timelines, even if the attributes themselves are named. These may be assembled onto timelines for ad-hoc purposes or they may just be used as any other descriptive attribute. A typical example would be the point of time the receipt for the stuff I bought on Black Friday was printed. You are not likely to name the timeline on which birth dates occur either.
In literature there are a couple of other names: User defined time [Snodgrass] and Happening time [Anchor]. Again, I’ve seen Transaction time used for unnamed times when the timepoint represents some event in which a transaction took place. Again, an unfortunate confusion of terminology.
Time Tracking Scope
Before implementing time in your database, you need to consider which of the timelines above and possibly others you will need, since they need to be separable in your database, possibly as different columns in the same or adjoined tables. Along with that you will also need to determine your time tracking scope. For example, is it sufficient to track changes to any part of an address or do you need to track changes of the individual parts of an address?
If tracking any change is sufficient, you can use a single point in time for the entire address. Essentially, you will be viewing a changed address, regardless of which part changed, as a new address. If you track the individual parts you will need several points in time, one for the street, one for the postal code, one for the state, and so on. In this case the same address can have different postal codes over time.
The latter approach, tracking time for every single object (attribute and relationship) can be achieved through modeling in the sixth normal form, henceforth 6NF. With it change is visible without having to make comparisons with previous rows and no data is duplicated when only a part of something is changing.
Even if you do not go as far as 6NF your time tracking scope has to be decided, since the amount of timepoints you will store depend on it. Unfortunately, in many of the source systems I regularly fetch data from, there is usually just one column named “modified date” which is documentary. In other words you can only tell something has changed and when, but not exactly what or what came before it. In these situations you can, with a proper data warehouse, provide the history the sources lost.
Orthogonality
If you have an implementation that keeps track of both appearance and assertion timepoints, this is usually referred to as a bi-temporal implementation. The reason is that events on the appearance timeline are in a sense orthogonal to events on the assertion timeline. It is possible for the same value to appear and to be asserted simultaneously, but also at different times, so a single timepoint is not sufficient to describe both events. Furthermore, what value appears may be retroactively corrected by a later assertion. When a value appears may be also modified by an assertion. Keeping both of these on the same timeline, if you think of it as storing the date and time in a single column in a table, would cause collisions and ambiguities.
When appearances and assertions are easy to tell apart, using two different timepoints to describe these may be complex but straightforward. Problems usually arise when you are faced with a different value but nobody can tell whether it is a correction of the existing value or supposed to replace it from some point in time. This may lead to corrupt data if the wrong assumptions are made. Another issue is the fact that if you want a bi-temporal implementation with both appearance and assertion timelines treated as primary, a single table with a single primary key cannot guarantee temporal integrity. This requires careful modeling, and only a few modeling techniques have this as a “built-in” feature.
Proxying
Some of the most confusing aspects of time in databases come from the use of proxying, whether deliberate or unknowingly. If we assume that I have decided to keep track of appearance, assertion, recording, and structuring timelines in my database, with 6NF time tracking scope, then I am very much all set for anything thrown at me from a querying perspective. However, that is under the assumption that all of those timepoints will be available to me when I put data into my database.
Sadly, this is often not the case. This is true both for operational systems and data warehouses. Getting information like [Using the Megastore structure as of January 5th (The database recorded on Monday 10:12:42 that ‘The manager asserted with 95% certainty on Monday at 09:15 that “The price cut will be 25% starting at midnight on Black Friday”‘)], actually never happens, yet. We do get some of the information some of the time though.
If we are in control of the database, we will always know when data is entering it. This opens up an opportunity. In the case that we do not know the assertion timepoint, say we only get “The price cut will be 25% starting at midnight on Black Friday”, we can approximate it with the recording timepoint. In this example that means missing the mark by almost an hour. As unfortunate as this is, sometimes it is the only option.
Somewhat more dangerous, but also doable, is approximating appearance timepoints with recording timepoints. Let’s say we only get “The price cut will be 25%” and we approximate it with the recording timepoint we will be dropping the price several days too early. Since recording timepoints always “happen” in the present when they come into existence, take utmost care when using it as an approximation for appearance timepoints. Still, this may sometimes also be the only option available.
Here within lies the big fallacy though. When enough approximations have been done, the different timelines become hard to distinguish, and it seems like you can use these timepoints interchangeably. This is not the case. You should always strive to get hold of the times when they are available and if proxying is necessary, and only as a last resort, then structure your loading intervals accordingly, to minimise the damage done.
Comparing Data Vault and Anchor
So far we have talked about time in databases from a theoretical perspective. There are two modeling techniques I would like to take a practical look at, taking diametrically different approaches to which timelines serve what purposes. The two techniques Anchor modeling and Data Vault are related, both being forms of Ensemble modeling, but still have many differences.
Anchor modeling utilises 6NF to provide as granular time tracking scope as possible. It designates the appearance and assertion timelines as primary for both attributes and relationships (called ties) around a concept (called anchor), while the recording timeline is documentary. Ties are attribute-like since they have a primary timeline and in that they have no identity of their own, making tie-to-tie and tie-to-attribute connections impossible, and tie-to-anchors the only option. Anchor also maintains separate metadata for the information structure in which structuring time is primary. By treating appearance and assertion timelines as primary, the database engine will ensure bi-temporal integrity. However, that needs both to be present and have functionally adequate approximations when necessary. Anchor also makes the assumption that values are exhaustive, such that an existing value cannot become NULL, and must instead be explicitly marked as “Unknown”. There no NULL values in an Anchor model.
Data Vault is similar to Anchor, but is not 6NF and instead groups attributes together (called satellites) around a concept (called hub). A single point of time is used to track all changes within a satellite, regardless of which particular attribute changed. The big difference is that Data Vault uses the recording timeline as primary for satellites. Relationships (called links) have no primary, but include a recording timepoint as documentary. Links are hub-like since they lack a primary, and can therefore have their own identities. Theoretically link-to-link and link-to-satellite connections then become possible. The implication is that relationships that change over time must be managed through other connected objects. Figuring out that some change occurred requires you to look outside of the link. Links are also, opposed to ties, always many to many, so any additional constraints have to be managed by the application layer. If appearance and assertion timelines are present in satellites or elsewhere pertain to links, they are always documentary. I do not believe Data Vault has a notion of a structuring timeline in its standard.
The advantage of Anchor is that you do not have to worry about temporal integrity after the data has entered the database. Integrity is also practically a requirement if you want to use the technique outside of data warehousing. Anchor was designed to be a general modeling technique and it is applied in several operational systems. The downside is that you need trustworthy timepoints, which can require a lot of effort and digging in the sources. Values in a source that once existed and suddenly are NULL could pose a problem if they are indeed suddenly “Unknown” and your data type does not support it to be explicitly specified. This has, in my experience, very rarely happened, and almost always the NULL means ‘deleted’, as in asserting the statement as false, which is a different thing and handled without problems. Analysts find it easy to work directly with Anchor models, thanks to it being able to serve data as it appears at or as it was asserted at without any additional work than finding the correct bitemporal time slice.
The advantage of Data Vault is that you do not have to worry at all about temporal integrity at load time. For auditing purposes, it will reproduce inconsistencies in the sources perfectly, so if you need to provide auditing and validation reports it is an excellent choice. Since Data Vault focuses specifically on data warehousing, it is also less restricted in its choice of primary timelines. However, using the recording timeline, the temporal integrity of the now documentary appearance and assertion timelines will likely have to be taken care of later. I do believe that if any business users are going to be using the data, this must be done at some point. Pushing constraints on links to the application layer has advantages if you, for example, want to prevent bigamous weddings for Christians, but allow polygamy for Mormons. The downside is that keeping consistency in a link requires more work than for a tie. In the end about the same amount of work will likely have to be done both in Anchor and Data Vault, but with additional layers in the latter. Looking at Data Vault and its choice of recording time as primary it looks like an excellent choice for a persistent staging layer, with the usually recommended Dimensional model on top as the presentable part of the data warehouse.
In my opinion both are valid options. If you like many layers, using different modeling techniques, distributing a fixed total amount of work over them, then Data Vault is a good choice. If you do not want layers, and stick to a single modeling technique, doing a fixed total amount of work for that single layer, then Anchor is a good choice. Both have been proven in practice, also for Big Data, but Data Vault has many more implementations to date.
Imprecision and Uncertainty
Going forward I am doing active research on transitional modeling, in which two other aspects of time is also considered. First there is imprecision. There is no way to measure time with perfect accuracy, so all timepoints are imprecise to some degree. In an atomic clock this imprecision is minuscule, but not insignificant. Regardless, there are events whose boundaries are hard to determine. Like when I got married. When exactly did that happen? Was it the moment I said “I do”? If it is, then my wife didn’t get married at the same point in time as me. By using fuzzy data types, intervals, or margins of error, we can actually express imprecision in databases. There are open questions on how to address the total ordering if we allow imprecise points of time in our primary timelines. Is it possible to maintain temporal integrity with imprecise values, or will we have to treat everything as documentary, and later apply some heuristics with best guesses?
The other aspect of time is uncertainty, which is not the same thing as imprecision. Certainty is a subjective measure, in which a statement is assessed with a “probability to be true”, loosely speaking. Using certainty it is actually possible to assert that you are certain of the opposite of a statement. This takes away a hard problem of storing ‘opposite values’ in a database by instead storing a negative certainty. Taking my marriage, if I look at “Lars was married on the 19th of June 2004” I can assert with 100% certainty that it is true, even if the time is imprecise enough to pin it down to a whole day. Looking at “Lars was married between 15:00 and 16:00 on the 19th of June 2004” I may actually be less certain, and assert it with 50% certainty, since I don’t exactly remember if it was one hour earlier or not. There are some open questions on when you contradict yourself if values are imprecise and you make several (vague) assertions. If values are precise, there is an exact formula by which you can calculate exactly when you contradict yourself.
Conclusions
Hopefully I have not made time all too confusing compared to the post of Christian that inspired me. I do believe that time in databases is a complex matter, but that should be digestible for everyone, given that we can put ourselves on some common ground. All the different terminology and poor implementations out there definitely does not help.
It’s time to treat time more seriously.